Contenido: Visualizaciones Generales | Voyant Tools | Orange Data Mining | AntConc
¿Qué visualizaciones contiene esta colección?
Esta sección reúne un conjunto de visualizaciones diseñadas para ofrecer una lectura general del corpus hemerográfico y de su organización interna. Las primeras gráficas presentan la distribución de los 229 artículos incluidos en la colección digital, permitiendo identificar tendencias por periódico, género periodístico y década. Adicionalmente, se incorporan algunos ejemplos de las visualizaciones generadas durante el exploratorio de datos realizado con herramientas de análisis textual. Estos análisis se basaron en 210 artículos procesados mediante OCR y ofrecen una muestra del trabajo computacional desarrollado en el proyecto. El análisis completo, así como la interpretación detallada de estos resultados, se encuentra en el documento escrito del trabajo de grado.
Visualizaciones generales
Cantidad de publicaciones por periódico
Esta visualización presenta la proporción de artículos de prensa incluidos en la colección según su medio de origen. Permite observar cómo se distribuye el corpus entre los distintos periódicos consultados. Esta distribución ofrece una primera aproximación a la diversidad de fuentes que documentaron el desarrollo del rock colombiano entre 1985 y 1995.
Cantidad de publicaciones por género periodístico
Este mapa de calor muestra la relación entre los periódicos consultados y los géneros periodísticos identificados en cada artículo. La visualización permite observar cómo se distribuyen estas categorías en el corpus y ofrece un panorama general de los enfoques narrativos presentes en la colección.
La categorización de géneros fue definida específicamente para este proyecto como una forma de organizar el corpus durante el análisis exploratorio. Aunque es una propuesta propia, proporciona un marco de referencia útil para reconocer variaciones en los tipos de contenido publicados a lo largo de la década.
Distribución de géneros por década
Este gráfico compara la cantidad de artículos publicados en los años ochenta y noventa según su género periodístico. La visualización permite observar cómo se distribuyen estas categorías a lo largo del periodo analizado y ofrece un panorama temporal que facilita comprender la composición del corpus en ambas décadas.
Voyant Tools
Voyant Tools fue la primera herramienta empleada para el análisis textual del corpus. Su interfaz permite explorar de manera general las palabras más frecuentes, las relaciones entre términos y la estructura global de los textos procesados. Las visualizaciones incluidas ofrecen una muestra de esta aproximación inicial y ejemplifican las posibilidades de lectura global que brinda la herramienta.
Resumen del Corpus
La vista Summary reúne varias métricas generales del corpus utilizado en el análisis textual, como la cantidad de documentos procesados, el total de palabras, el número de términos únicos y la longitud relativa de los textos. También incluye indicadores como la densidad de vocabulario, el promedio de palabras por oración y las palabras distintivas de cada documento. Estas medidas permiten obtener una visión preliminar de la composición y las características globales del corpus.
Nube de palabras
La visualización Cirrus muestra las palabras más frecuentes del corpus mediante una representación proporcional a su recurrencia. Esta nube de términos permite identificar de manera rápida los conceptos que aparecen con mayor regularidad en los textos procesados y ofrece una lectura panorámica del vocabulario predominante en el corpus.
Racimo de términos
La visualización TermsBerry presenta un conjunto de términos destacados del corpus mediante círculos cuyo tamaño está asociado a su frecuencia. A diferencia de la nube de palabras, esta vista permite identificar también la cantidad de documentos en los que aparece cada término al situar el cursor sobre ellos. Esta representación complementa la lectura global del vocabulario del corpus y facilita reconocer la dispersión de los términos a lo largo de los textos procesados.
Términos frecuentes
La visualización Terms presenta un listado de las palabras más frecuentes del corpus acompañado de su conteo exacto y de la gráfica “Trend”, que muestra su comportamiento a lo largo de los textos. Esta vista complementa la información ofrecida por Cirrus y TermsBerry, ya que permite comparar la recurrencia de los términos con mayor precisión y observar su distribución dentro del corpus. Con ello, proporciona una lectura más detallada del vocabulario dominante.
Relación entidades detectadas por Voyant Tools
La visualización RezoViz muestra una red de entidades identificadas en el corpus, como nombres propios, lugares y organizaciones. Cada nodo representa una entidad y las líneas señalan las veces en que aparecen juntas dentro de los textos. Aunque Voyant Tools no detectó la totalidad de las entidades presentes en los artículos, esta vista complementa las aproximaciones léxicas anteriores y ofrece una visión general de las conexiones entre entidades que se dan a lo largo del corpus.
Orange Data Mining
Las visualizaciones realizadas en Orange Data Mining complementan la lectura global obtenida con Voyant Tools mediante tres aproximaciones diferentes: la identificación automática de palabras clave, la agrupación de artículos según su similitud lingüística y la evaluación del tono emocional del corpus. Juntas, estas vistas permiten apreciar aspectos más finos del discurso periodístico sobre el rock en Colombia y ofrecen una mirada comparativa entre relevancia léxica, organización temática y polaridad del lenguaje.
Extracción de palabras clave (YAKE! + RAKE)
Esta visualización presenta las palabras clave identificadas automáticamente mediante los algoritmos de extracción YAKE! y Rake. A diferencia de las frecuencias generales del vocabulario, estos métodos señalan los términos más relevantes según su papel dentro del discurso. La selección resultante refina la lectura del corpus y permite identificar conceptos centrales como rock, grupo, concierto o Bogotá, que organizan gran parte de la narrativa periodística sobre la escena musical.

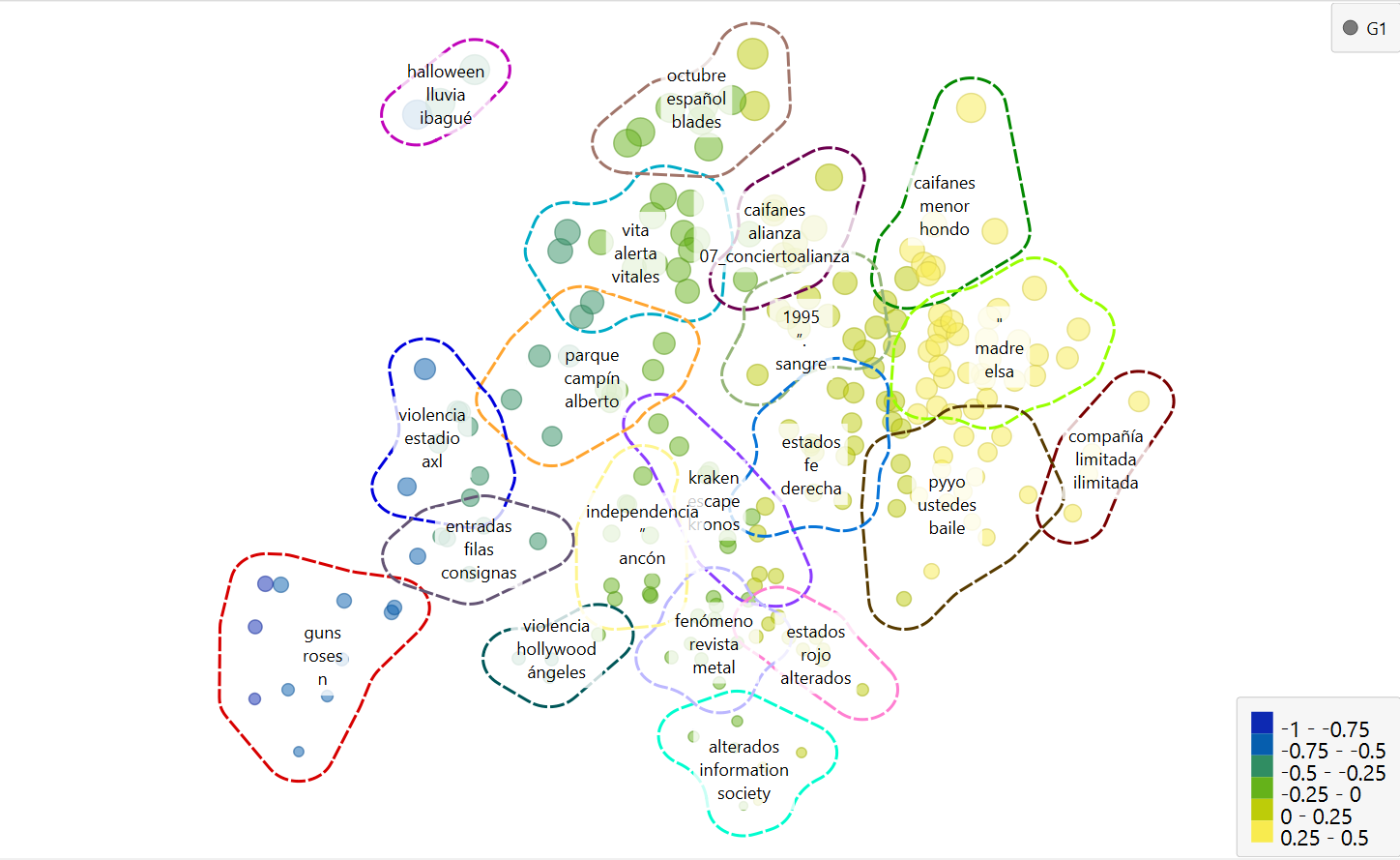
Mapa del corpus (t-SNE)
El mapa del corpus muestra una representación aproximada de la similitud lingüística entre los artículos, agrupándolos según patrones compartidos de vocabulario. Esta proyección permite observar zonas temáticas donde convergen textos relacionados con conciertos, violencia, festivales, artistas o coyunturas específicas. La visualización ofrece así una mirada global a la estructura interna del corpus y a sus afinidades discursivas.
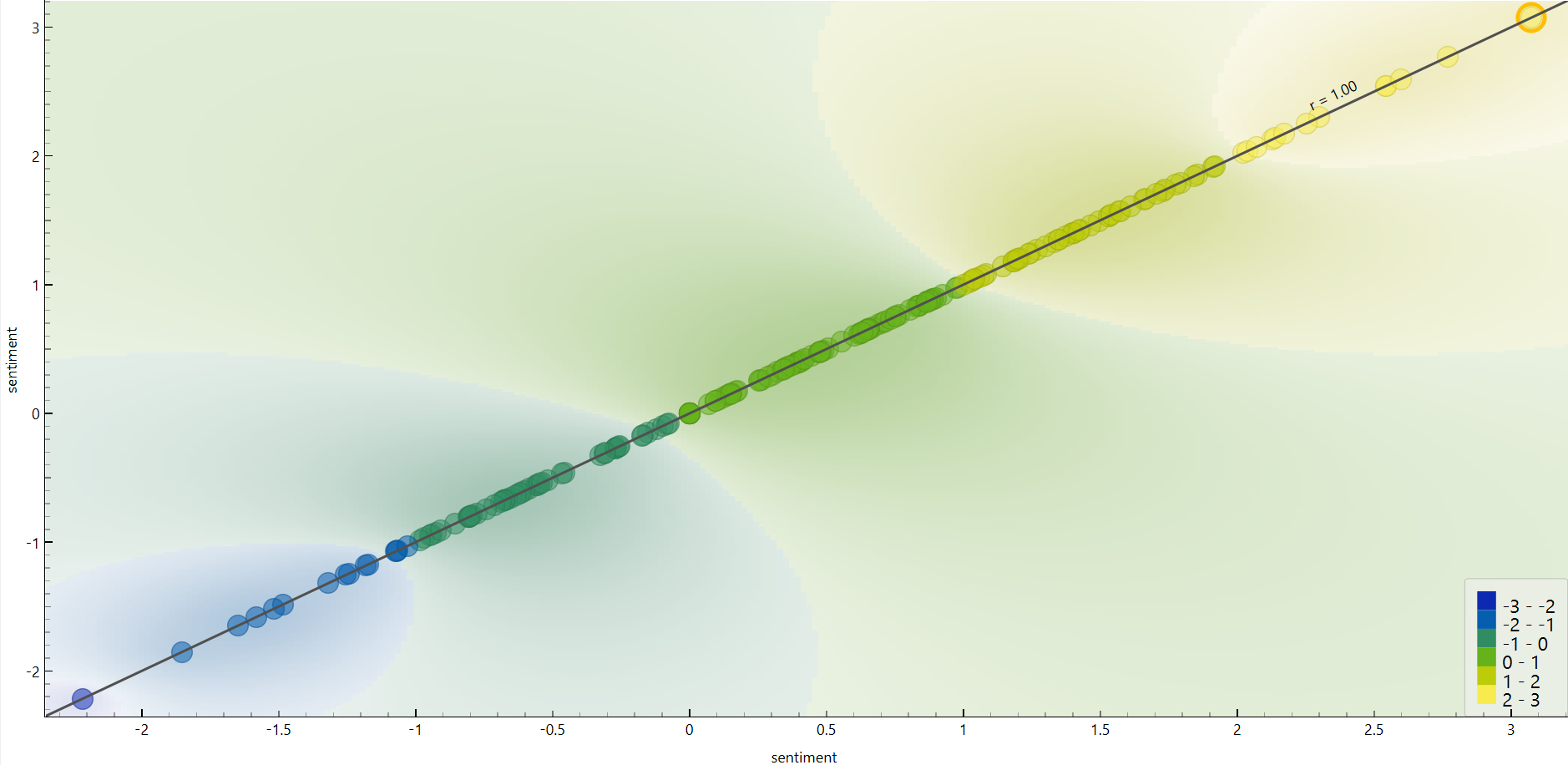
Análisis de sentimiento
Esta visualización muestra los valores de sentimiento asignados automáticamente a cada artículo, ubicados en un rango continuo entre polos negativos, neutros y positivos. Los resultados se concentran mayoritariamente en niveles intermedios, lo que sugiere que el discurso periodístico sobre el rock en Colombia no estuvo dominado por tonos marcadamente negativos. Aunque se trata de una aproximación automatizada, la gráfica aporta un indicio general sobre la carga emocional del lenguaje utilizado en los textos.
AntConc
AntConc fue la tercera herramienta empleada en el análisis textual del corpus. A diferencia de Voyant Tools y Orange Data Mining, que ofrecen vistas globales del vocabulario y de la estructura de los documentos, AntConc permite realizar búsquedas focalizadas y observar de manera puntual cómo aparecen determinadas palabras dentro de los textos. Las visualizaciones incluidas en esta sección presentan ejemplos de estos patrones mediante clusters, collocates y concordancias (KWIC), que muestran combinaciones frecuentes, palabras asociadas y fragmentos originales del corpus donde cada término aparece acompañado por el texto que lo rodea.
Combinaciones frecuentes de palabras asociadas al término “rock”
La visualización de clusters muestra las secuencias de dos palabras que aparecen con mayor frecuencia junto al término rock dentro del corpus. AntConc identifica estos patrones a partir de combinaciones recurrentes en los textos, agrupando las palabras que forman unidades léxicas habituales como rock nacional, rock colombiano, rock pesado o rock latino. Este tipo de consulta permite observar cómo el término se articula con otros adjetivos o nociones dentro de las noticias, revelando las expresiones que los artículos repiten con mayor regularidad.

Palabras frecuentes junto al término “rock”
La visualización de collocates presenta las palabras que aparecen con mayor frecuencia junto al término rock dentro del corpus, calculadas a partir de su proximidad inmediata en los textos. AntConc identifica estas coocurrencias mediante conteos literales y las ordena según medidas estadísticas como la frecuencia, el rango y la verosimilitud (likelihood). En este caso, los términos asociados incluyen expresiones como español, nacional, colombiano, pesado, pop o latino, entre otros. Esta vista permite observar qué palabras tienden a aparecer cerca del término buscado y cuáles forman combinaciones recurrentes en el corpus.

Contextos término “rock”
La vista KWIC (Key Word in Context) de AntConc permite observar el término rock dentro de su entorno inmediato en los textos del corpus. La herramienta muestra, en columnas separadas, el fragmento previo al término, la palabra buscada y el fragmento que aparece a su derecha. El resultado presenta una lista de todas las apariciones de rock en los artículos, organizada línea por línea para facilitar la lectura comparada. Esta visualización permite identificar de manera rápida las palabras y expresiones que suelen acompañar al término en el corpus, así como los contextos textuales en los que aparece.
